
4·
2 hours agoWith that many Windows (gasp) ones, no… I’m afraid you are not
With that many Windows (gasp) ones, no… I’m afraid you are not
endeavors
Holy shit
 acknowledgement??
acknowledgement??
Making up an example on the spot is kinda difficult for me, but I’d look at it this way with a bold statement, you should hope that most code won’t need comments. Let’s exclude documentation blocks that are super ok to be redundant as they should give a nice, consistent, human readable definition of what x thing does (function, constant, enum, etc.) and maybe even how to use it if it’s non-intuitive or there are some quirks with it.
After that, you delve in the actual meat of the code, there are ways to make it more self explanatory like extracting blocks of stuff into functions, even when you don’t think it’ll be used again, to be used with care though, as not to make a million useless functions, better is to structure your code so that an API is put into place, enabling you to write code that naturally comes out high level enough to be understood just by reading, this thing is very difficult for me to pinpoint though, because we think of high level code as abstractions, something that turns the code you write from describing the what rather than the how, but really, it’s a matter of scope, a print statement is high level if the task is to print, but if the task is to render a terminal interface then the print becomes low level, opposite is also true, if you go down and your task is to put a character onto stdout, then the assembly code you’d write might be high level. What I mean to say is that, once you have defined the scope, then you can decide what level of knowledge to expect of the reader when looking at your code, from there, if some process feels fairly convoluted, but it doesn’t make sense to build an abstraction over it, then it is a good place to put a comment explaining why you did that, and, if it’s not really clear, even what that whole block does

Did a bit more research, was thinking it might be a systemd service, so I checked for timers there, but there was just a countme timer enabled that basically tells the server to include you in the count of active systems (how to disable, for the paranoid 🥸).
Then I went on to look at the live logs of rpm-ostree and, as found from this website used this command:
journalctl --follow --unit rpm-ostreed.service
So that I could monitor its activity while I open Discover and so I managed to record when it happens, I also saw from the logs that there is a configuration file at this path /etc/rpm-ostreed.confand that you can configure automatic updates from there, by default there a this line about it (usage greatly explained with man rpm-ostreed.conf btw):
[Daemon]
#AutomaticUpdatePolicy=none
but it’s commented out, so it couldn’t have been that.
Finally there is this one thing that pops up in the logs:
Initiated txn AutomaticUpdateTrigger for client(id:cli dbus:1.1625 unit:app-org.kde.discover@df0f43f8979843c0a34d36ad199c7eda.service uid:1000): /org/projectatomic/rpmostree1/fedora
So it is something triggered by Discover, as I had known already, due to other articles that talk about the integration with Discover, but I wasn’t so sure about it anymore, since I couldn’t find any related settings in the app.
So I found the setting that configures automatic updates in general… in the three dot menu (questionable UX decision?):
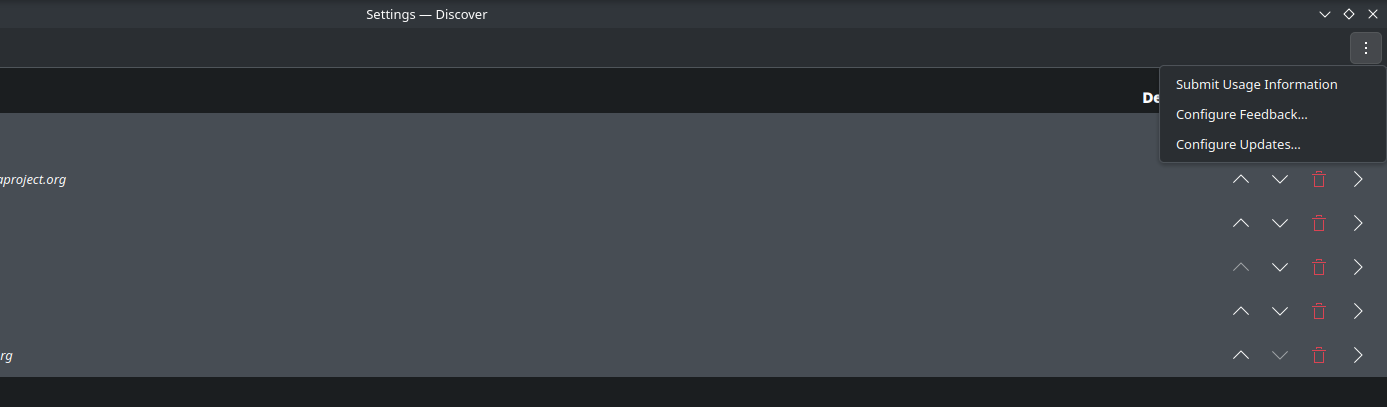
which actually just leads to the system settings:
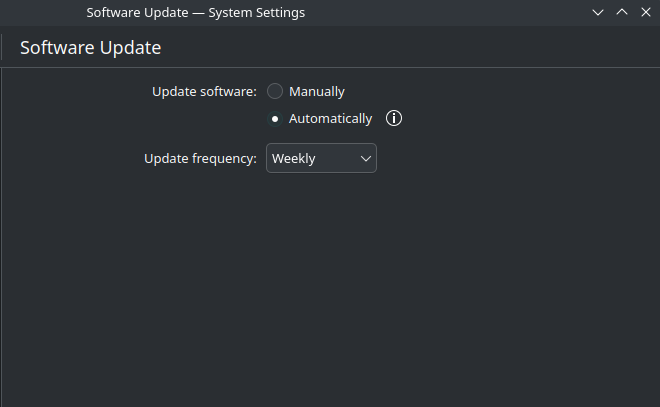
I had this configured to be weekly, there isn’t even a setting as granular as seconds, the smallest span of time is daily, but what I’m guessing is that the “Update frequency” acts on when they should be installed automatically rather than when they should be fetched, so this is a limitation of the system as I understand it
Will do, hopefully there is one

That is insanely cool, but isn’t it even more manual? ( °ヮ° ᵕ)

You were far ahead of professors that make you write it out with pen and paper
Why so irritable? I’m just asking, I don’t even know German, I thought since you knew the video already, you could point me in the right direction, rather than me having to sift through it all while also passing it through a translator to hopefully (because I don’t know how well youtube’s auto-translate feature works) find the information I’m looking for in the whole presentation
On a quick skim I don’t see a way on it to set volume profiles, let alone program behavior based on certain events, is there some menu I might have missed?
So what I’m getting is that I would have to come up with something myself, right? I mean that would be super cool to do, but I don’t have the time to put into that, unfortunately
This is the architecture though, I’m asking about an application that can interact with it
55 minutes? Uhm, could you tell me the relevant section of the video, please?
nuff said.
I see, I guess that’s what happened to those that broke for me
I used to prefer GNOME, until I started using KDE daily on the desktop, I thought it would just be temporary, but I ended up liking KDE way more because of the features that are built-in, the integration is simply priceless and I’m tired of those GNOME extensions that keep breaking at the next GNOME major release and I have to wait weeks for the poor devs to catch up and fix them up to get the compatibility going again, in some ways that also happens on KDE with the widgets, but, arguably, you will need way fewer of those to extend the already wide functionality provided by the Fedora KDE experience, so you risk incurring in that issue a lot less. Note I specifically mention Fedora both because it’s the system you want and because the pool of apps included is the best for a streamlined, but not bloated, experience, which also allows me to use Kinoite without troubling myself to overlay crucial apps that aren’t provided (or don’t work fully) as Flatpak.

I’m glad that it’s coming natively, but hands down there’s a whole lot of progress they have yet to make to come close to the usability provided by Sidebery, good that they’re also working on native vertical tabs in fact! So I think that if you’re looking for a better system you could try out that extension https://addons.mozilla.org/en-US/firefox/addon/sidebery/
AGPL on documentation? What would that do?

I wholeheartedly agree with what you say, I think I’ll leave it be, anyways I’m not against if any other mod steps in to delete, I’m just sorry that I have to go back on my word of being merely a collector of votes, in the end I really do think this is a useful record to keep and it wouldn’t be in me to take action against it by erasing, because I think the better action against it is to let others to see for themselves and learn by seeing how the wrong stance is disproved
Yeah, though I am still quite unsure, the majority were for removing: 2 that have reached out again, against none other than you who agreed on keeping, factoring in the initial reporters, 5, minus 1 who I count from before, I think I should still remove.
I’m actually past the deadline I gave myself but I want to hear what you think first









{kind=link}
{kind=link}
Yes, I feel like some kind of bell should ring in your brain when something needs to be commented, most often if you struggled to write out the solution or you had to do a lot of digging from various places to achieve the final resulting piece of code, it doesn’t make a lot of sense to pressure yourself into thinking you should comment everything, because some knowledge has to be assumed, nowadays you could even add that if someone completely extraneous to the codebase entered without any knowledge, they could feed the parts of code they need to understand into some LLM to get a feel for what they’re looking at, with further feedback from actual devs though, you never know what random bs they might write.
Good one on the variables to store results of expressions, I agree with that method, though I always forget to do that because I get so lost in the pride of writing that convoluted one-liner that I think, “oh yeah, this is perfectly beautiful and understandable 😇”, I have to check myself more on that.
So I’m not alone on that haha.
Sorry, what’s the subject of that?